Goland面试题
基础
什么是Go语言?Go语言的特点是什么?
Go语言是一种开源的编程语言,由Google公司开发。它具有高效、简洁、安全等特点。Go语言支持并发编程,可以更好地利用多核处理器的能力。同时,Go语言还拥有垃圾回收、自动类型推断、内置函数等特性。
Go语言的优缺点是什么?
优点:
- 编译速度快,执行速度快。
- 内存管理自动化,支持垃圾回收。
- 并发模型简单,支持大规模并发。
- 语言结构简洁,易于学习和使用。
- 支持跨平台,可以在不同的操作系统上运行。
缺点:
- 对于一些底层的操作,需要手动实现。
- 类型系统不够强,类型转换的限制较少。
- 反射机制的性能较差。
make和new的区别?
1)作用变量类型不同,new给string,int和数组分配内存,make给切片,map,channel分配内存;
2)返回类型不一样,new返回指向变量的指针,make返回变量本身;
3)new 分配的空间被清零。make 分配空间后,会进行初始化;
数组和切片的区别?
1)数组是定长,访问和复制不能超过数组定义的长度,否则就会下标越界,切片长度和容量可以自动扩容;
2)数组是值类型,切片是引用类型,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是这底层数组存储数据,所以修改切片的时候修改的是底层数组中的数据。切片一旦扩容,指向一个新的底层数组,内存地址也就随之改变
方法与函数的区别?
在Go语言中,函数和方法不太一样,有明确的概念区分。其他语言中,比如Java,一般来说函数就是方法,方法就是函数;但是在Go语言中,函数是指不属于任何结构体、类型的方法,也就是说函数是没有接收者的;而方法是有接收者的。
//方法
func (t *T) add(a, b int) int {
return a + b
}
// 其中T是自定义类型或者结构体,不能是基础数据类型int等
//函数
func add(a, b int) int {
return a + b
}
方法值接收者和指针接收者的区别?
如果方法的接收者是指针类型,无论调用者是对象还是对象指针,修改的都是对象本身,会影响调用者;
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;
type Person struct {
age int
}
// 如果实现了接收者是指针类型的方法,会隐含地也实现了接收者是值类型的IncrAge1方法。
// 会修改age的值
func (p *Person) IncrAge1() {
p.age += 1
}
// 如果实现了接收者是值类型的方法,会隐含地也实现了接收者是指针类型的IncrAge2方法。
// 不会修改age的值
func (p Person) IncrAge2() {
p.age += 1
}
// 如果实现了接收者是值类型的方法,会隐含地也实现了接收者是指针类型的GetAge方法。
func (p Person) GetAge() int {
return p.age
}
func main() {
// p1 是值类型
p := Person{age: 10}
// 值类型 调用接收者是指针类型的方法
p.IncrAge1()
fmt.Println(p.GetAge()) //11
// 值类型 调用接收者是值类型的方法
p.IncrAge2()
fmt.Println(p.GetAge()) //11
// ----------------------
// p2 是指针类型
p2 := &Person{age: 20}
// 指针类型 调用接收者是指针类型的方法
p2.IncrAge1()
fmt.Println(p2.GetAge()) //21
// 指针类型 调用接收者是值类型的方法
p2.IncrAge2()
fmt.Println(p2.GetAge())//21
}
函数返回局部变量的指针是否安全
一般来说,局部变量会在函数返回后被销毁,因此被返回的引用就成为了”无所指”的引用,程序会进入未知状态。
但这在 Go 中是安全的,Go 编译器将会对每个局部变量进行逃逸分析。如果发现局部变量的作用域超出该函数,则不会将内存分配在栈上,而是分配在堆上,因为他们不在栈区,即使释放函数,其内容也不会受影响。
func add(x, y int) *int {
res := 0
res = x + y
return &res
}
func main() {
fmt.Println(add(1, 2))
}
// 编译时可以借助选项 -gcflags=-m,查看变量逃逸的情况
./main.go:6:2: res escapes to heap:
./main.go:6:2: flow: ~r2 = &res:
./main.go:6:2: from &res (address-of) at ./main.go:8:9
./main.go:6:2: from return &res (return) at ./main.go:8:2
./main.go:6:2: moved to heap: res
./main.go:12:13: ... argument does not escape 0xc0000ae008
res escapes to heap 即表示 res 逃逸到堆上了。
uintptr与unsafe.Pointer区别?
unsafe.Pointer 是通用指针类型,它不能参与计算,任何类型的指针都可以转化成 unsafe.Pointer,unsafe.Pointer 可以转化成任何类型的指针,uintptr 可以转换为 unsafe.Pointer,unsafe.Pointer 可以转换为 uintptr。uintptr 是指针运算的工具,但是它不能持有指针对象(意思就是它跟指针对象不能互相转换),unsafe.Pointer 是指针对象进行运算(也就是 uintptr)的桥梁。
Slice
array和slice的区别?
数组长度不能改变,初始化后长度就是固定的;切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
结构不同,数组是一串固定数据,切片描述的是截取数组的一部分数据,从概念上说是一个结构体。
初始化方式不同,如上。另外在声明时的时候:声明数组时,方括号内写明了数组的长度或使用...自动计算长度,而声明slice时,方括号内没有任何字符。
函数调用时的传递方式不同,数组按值传递,slice按引用传递。
func main() {
s := []int{1, 2, 3}
s1 := s[0:1]
PrintSlice(s1) // [1,4]
fmt.Println(s) // [1,4,3]
fmt.Println(s1) // [1]
}
func PrintSlice(s []int) {
s = append(s, 4)
fmt.Println(s)
}
slice深拷贝和浅拷贝
深拷贝:拷贝的是数据本身,创造一个新对象,新创建的对象与原对象不共享内存,新创建的对象在内存中开辟一个新的内存地址,新对象值修改时不会影响原对象值、
实现深拷贝的方式:
- copy(slice2, slice1)
- 遍历append赋值
func main() {
slice1 := []int{1, 2, 3, 4, 5}
slice2 := make([]int, 5, 5)
fmt.Printf("slice1: %v, %p", slice1, slice1)
copy(slice2, slice1)
fmt.Printf("slice2: %v, %p", slice2, slice2)
slice3 := make([]int, 0, 5)
for _, v := range slice1 {
slice3 = append(slice3, v)
}
fmt.Printf("slice3: %v, %p", slice3, slice3)
}
slice1: [1 2 3 4 5], 0xc0000b0030
slice2: [1 2 3 4 5], 0xc0000b0060
slice3: [1 2 3 4 5], 0xc0000b0090
浅拷贝:拷贝的是数据地址,只复制指向的对象的指针,此时新对象和老对象指向的内存地址是一样的,新对象值修改时老对象也会变化
func main() {
slice1 := []int{1, 2, 3, 4, 5}
fmt.Printf("slice1: %v, %p", slice1, slice1)
slice2 := slice1
fmt.Printf("slice2: %v, %p", slice2, slice2)
}
slice1: [1 2 3 4 5], 0xc00001a120
slice2: [1 2 3 4 5], 0xc00001a120
slice扩容机制?
扩容会发生在slice append的时候,当slice的cap不足以容纳新元素,就会进行扩容,扩容规则如下
- 如果新申请容量比两倍原有容量大,那么扩容后容量大小 为 新申请容量
- 如果原有 slice 长度小于 1024, 那么每次就扩容为原来的 2 倍
- 如果原 slice 长度大于等于 1024, 那么每次扩容就扩为原来的 1.25 倍
func main() {
slice1 := []int{1, 2, 3}
for i := 0; i < 16; i++ {
slice1 = append(slice1, 1)
fmt.Printf("addr: %p, len: %v, cap: %v", slice1, len(slice1), cap(slice1))
}
}
addr: 0xc00001a120, len: 4, cap: 6
addr: 0xc00001a120, len: 5, cap: 6
addr: 0xc00001a120, len: 6, cap: 6
addr: 0xc000060060, len: 7, cap: 12
addr: 0xc000060060, len: 8, cap: 12
addr: 0xc000060060, len: 9, cap: 12
addr: 0xc000060060, len: 10, cap: 12
addr: 0xc000060060, len: 11, cap: 12
addr: 0xc000060060, len: 12, cap: 12
addr: 0xc00007c000, len: 13, cap: 24
addr: 0xc00007c000, len: 14, cap: 24
addr: 0xc00007c000, len: 15, cap: 24
addr: 0xc00007c000, len: 16, cap: 24
addr: 0xc00007c000, len: 17, cap: 24
addr: 0xc00007c000, len: 18, cap: 24
addr: 0xc00007c000, len: 19, cap: 24
slice为什么不是线程安全的?
slice底层结构并没有使用加锁等方式,不支持并发读写,所以并不是线程安全的,使用多个 goroutine 对类型为 slice 的变量进行操作,每次输出的值大概率都不会一样,与预期值不一致; slice在并发执行中不会报错,但是数据会丢失
func TestSliceConcurrencySafe(t *testing.T) {
a := make([]int, 0)
var wg sync.WaitGroup
for i := 0; i < 10000; i++ {
wg.Add(1)
go func(i int) {
a = append(a, i)
wg.Done()
}(i)
}
wg.Wait()
t.Log(len(a))
// not equal 10000
}
扩容前后的 Slice 是否相同?
情况一:
原数组还有容量可以扩容(实际容量没有填充完),这种情况下,扩容以后的数组还是指向原来的数组,对一个切片的操作可能影响多个指针指向相同地址 的 Slice。
情况二:
原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响 原数组。
要复制一个 Slice,最好使用 Copy 函数。
slice分配在堆上还是栈上
有可能分配到栈上,也有可能分配到栈上。当开辟切片空间较大时,会逃逸到堆上。
Channel
Go channel有什么特点?
channel有2种类型:无缓冲、有缓冲
channel有3种模式:写操作模式(单向通道)、读操作模式(单向通道)、读写操作模式(双向通道)
| 写操作模式 | 读操作模式 | 读写操作模式 | |
|---|---|---|---|
| 创建 | make(chan<- int) | make(<-chan int) | make(<-chan int) |
channel有3种状态:未初始化、正常、关闭
| 未初始化 | 关闭 | 正常 | |
|---|---|---|---|
| 关闭 | panic | panic | 正常关闭 |
| 发送 | 永远阻塞导致死锁 | panic | 阻塞或者成功发送 |
| 接收 | 永远阻塞导致死锁 | 缓冲区为空则为零值,否则可以继续 | 阻塞或者成功接收 |
注意点:
- 一个 channel不能多次关闭,会导致painc
- 如果多个 goroutine 都监听同一个 channel,那么 channel 上的数据都可能随机被某一个 goroutine 取走进行消费
- 如果多个 goroutine 监听同一个 channel,如果这个 channel 被关闭,则所有 goroutine 都能收到退出信号
Go channel的底层实现原理?
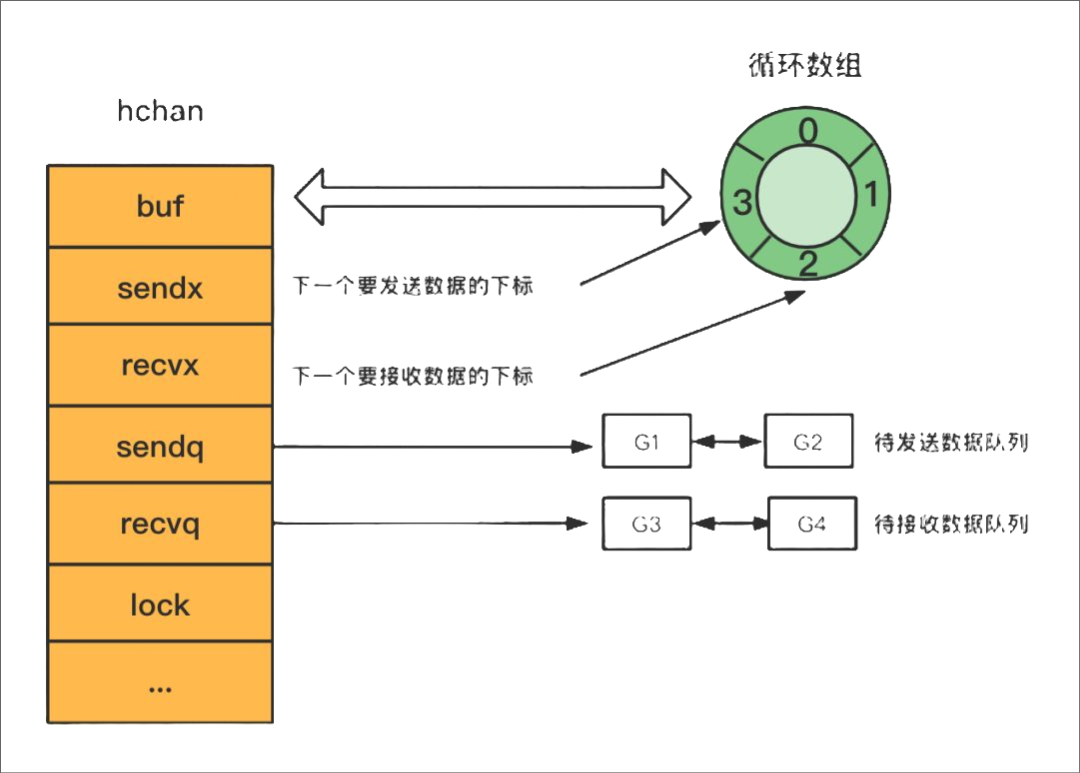
底层结构需要描述出来,这个简单,buf,发送队列,接收队列,lock。
发送
向 channel 中发送数据时大概分为两大块:检查和数据发送,数据发送流程如下:
- 如果 channel 的读等待队列存在接收者goroutine
- 将数据直接发送给第一个等待的 goroutine, 唤醒接收的 goroutine
- 如果 channel 的读等待队列不存在接收者goroutine
- 如果循环数组buf未满,那么将会把数据发送到循环数组buf的队尾
- 如果循环数组buf已满,这个时候就会走阻塞发送的流程,将当前 goroutine 加入写等待队列,并挂起等待唤醒
接收
向 channel 中接收数据时大概分为两大块,检查和数据发送,而数据接收流程如下:
- 如果 channel 的写等待队列存在发送者goroutine
- 如果是无缓冲 channel,直接从第一个发送者goroutine那里把数据拷贝给接收变量,唤醒发送的 goroutine
- 如果是有缓冲 channel(已满),将循环数组buf的队首元素拷贝给接收变量,将第一个发送者goroutine的数据拷贝到 buf循环数组队尾,唤醒发送的 goroutine
- 如果 channel 的写等待队列不存在发送者goroutine
- 如果循环数组buf非空,将循环数组buf的队首元素拷贝给接收变量
- 如果循环数组buf为空,这个时候就会走阻塞接收的流程,将当前 goroutine 加入读等待队列,并挂起等待唤醒
总结hchan结构体的主要组成部分有四个:
- 用来保存goroutine之间传递数据的循环数组:buf
- 用来记录此循环数组当前发送或接收数据的下标值:sendx和recvx
- 用于保存向该chan发送和从该chan接收数据被阻塞的goroutine队列: sendq 和 recvq
- 保证channel写入和读取数据时线程安全的锁:lock
使用场景: 消息传递、消息过滤,信号广播,事件订阅与广播,请求、响应转发,任务分发,结果汇总,并发控制,限流,同步与异步
请解释一下Go语言的协程和并发模型
Go channel有无缓冲的区别?
| 无缓冲 | 有缓冲 | |
|---|---|---|
| 创建方式 | make(chan TYPE) | make(chan TYPE,SIZE) |
| 发送阻塞 | 数据接收前发送阻塞 | 缓冲满时发送阻塞 |
| 接收阻塞 | 数据发送前接收阻塞 | 缓冲空时接收阻塞 |
Go channel为什么是线程安全的?
为什么设计成线程安全?
不同协程通过channel进行通信,本身的使用场景就是多线程,为了保证数据的一致性,必须实现线程安全
如何实现线程安全的?
channel的底层实现中,hchan结构体中采用Mutex锁来保证数据读写安全。在对循环数组buf中的数据进行入队和出队操作时,必须先获取互斥锁,才能操作channel数据
Map
map的底层实现原理

Go中的map是一个指针,占用8个字节,指向hmap结构体
源码包中src/runtime/map.go定义了hmap的数据结构:
hmap包含若干个结构为bmap的数组,每个bmap底层都采用链表结构,bmap通常叫其bucket
hmap结构体
// A header for a Go map.
type hmap struct {
count int
// 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
flags uint8
// 状态标志(是否处于正在写入的状态等)
B uint8
// buckets(桶)的对数
// 如果B=5,则buckets数组的长度 = 2^B=32,意味着有32个桶
noverflow uint16
// 溢出桶的数量
hash0 uint32
// 生成hash的随机数种子
buckets unsafe.Pointer
// 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。
oldbuckets unsafe.Pointer
// 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。
nevacuate uintptr
// 表示扩容进度,小于此地址的buckets代表已搬迁完成。
extra *mapextra
// 存储溢出桶,这个字段是为了优化GC扫描而设计的,下面详细介绍
}
bmap结构体
bmap 就是我们常说的“桶”,一个桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果的低B位是相同的,关于key的定位我们在map的查询中详细说明。在桶内,又会 根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
// len为8的数组
// 用来快速定位key是否在这个bmap中
// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}
上面bmap结构是静态结构,在编译过程中runtime.bmap会拓展成以下结构体:
type bmap struct{
tophash [8]uint8
keys [8]keytype
// keytype 由编译器编译时候确定
values [8]elemtype
// elemtype 由编译器编译时候确定
overflow uintptr
// overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
tophash就是用于实现快速定位key的位置,在实现过程中会使用key的hash值的高8位作为tophash值,存放在bmap的tophash字段中
tophash字段不仅存储key哈希值的高8位,还会存储一些状态值,用来表明当前桶单元状态,这些状态值都是小于minTopHash的
为了避免key哈希值的高8位值和这些状态值相等,产生混淆情况,所以当key哈希值高8位若小于minTopHash时候,自动将其值加上minTopHash作为该key的tophash。桶单元的状态值如下:
emptyRest = 0 // 表明此桶单元为空,且更高索引的单元也是空
emptyOne = 1 // 表明此桶单元为空
evacuatedX = 2 // 用于表示扩容迁移到新桶前半段区间
evacuatedY = 3 // 用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 // 用于表示此单元已迁移
minTopHash = 5 // key的tophash值与桶状态值分割线值,小于此值的一定代表着桶单元的状态,大于此值的一定是key对应的tophash值
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
mapextra结构体
当map的key和value都不是指针类型时候,bmap将完全不包含指针,那么gc时候就不用扫描bmap。bmap指向溢出桶的字段overflow是uintptr类型,为了防止这些overflow桶被gc掉,所以需要mapextra.overflow将它保存起来。如果bmap的overflow是*bmap类型,那么gc扫描的是一个个拉链表,效率明显不如直接扫描一段内存(hmap.mapextra.overflow)
type mapextra struct {
overflow *[]*bmap
// overflow 包含的是 hmap.buckets 的 overflow 的 buckets
oldoverflow *[]*bma
// oldoverflow 包含扩容时 hmap.oldbuckets 的 overflow 的 bucket
nextOverflow *bmap
// 指向空闲的 overflow bucket 的指针
}
总结
bmap(bucket)内存数据结构可视化如下:
注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式,当key和value类型不一样的时候,key和value占用字节大小不一样,使用key/value这种形式可能会因为内存对齐导致内存空间浪费,所以Go采用key和value分开存储的设计,更节省内存空间
Go map如何查找?
Go 语言中读取 map 有两种语法:带 comma 和 不带 comma。当要查询的 key 不在 map 里,带 comma 的用法会返回一个 bool 型变量提示 key 是否在 map 中;而不带 comma 的语句则会返回一个 value 类型的零值。如果 value 是 int 型就会返回 0,如果 value 是 string 类型,就会返回空字符串。
// 不带 comma 用法
value := m["name"]
fmt.Printf("value:%s", value)
// 带 comma 用法
value, ok := m["name"]
if ok {
fmt.Printf("value:%s", value)
}
map的查找通过生成汇编码可以知道,根据 key 的不同类型/返回参数,编译器会将查找函数用更具体的函数替换,以优化效率:
| key 类型 | 查找 |
|---|---|
| uint32 | mapaccess1_fast32(t maptype, h hmap, key uint32) unsafe.Pointer |
| uint32 | mapaccess2_fast32(t maptype, h hmap, key uint32) (unsafe.Pointer, bool) |
| uint64 | mapaccess1_fast64(t maptype, h hmap, key uint64) unsafe.Pointer |
| uint64 | mapaccess2_fast64(t maptype, h hmap, key uint64) (unsafe.Pointer, bool) |
| string | mapaccess1_faststr(t maptype, h hmap, ky string) unsafe.Pointer |
| string | mapaccess2_faststr(t maptype, h hmap, ky string) (unsafe.Pointer, bool) |
查找流程
Go语言采用了基于CSP(Communicating Sequential Processes)的并发模型,通过goroutine(协程)来实现。goroutine是一种轻量级的线程,可以在Go语言的运行时(runtime)中自由地调度。通过goroutine,可以轻松地实现并发和并行。
Go语言的垃圾回收机制是怎样的?
Go语言的垃圾回收机制采用了标记-清除算法。在Go语言中,当一个对象不再被引用时,垃圾回收器会自动回收这个对象所占用的内存空间。垃圾回收器会周期性地遍历程序中的所有对象,标记那些还在使用中的对象,然后清除那些已经不再使用的对象。如何在Go语言中实现线程安全?
Go语言提供了一些机制来实现线程安全,如互斥锁、读写锁、原子操作等。互斥锁可以在多个goroutine之间保证数据的互斥访问,读写锁则可以在读多写少的情况下提高程序的性能。原子操作可以保证对变量的操作是原子性的,不会出现竞争条件。请解释一下Go语言的标准库
Go语言的标准库提供了一系列常用的功能,如网络编程、文件操作、加密解密、时间日期处理等。标准库的设计注重于可读性和可维护性,大部分功能都有详细的文档和示例代码请解释一下Go语言的接口实现原理
在Go语言中,接口是一种类型,通过定义方法集来描述类型的行为。一个类型只需要实现接口定义的方法,就可以成为这个接口的实现。Go语言中的接口是隐式实现的,即一个类型只要实现了接口定义的方法,就自动成为这个接口的实现。请解释一下Go语言的反射机制
Go语言的反射机制可以在运行时动态地获取一个变量的类型信息和值。通过反射,可以实现一些高级的功能,如动态创建类型、调用任意函数、动态修改变量等。在Go语言中,反射主要通过reflect包来实现如何在Go语言中进行错误处理?
在Go语言中,错误是一种类型,通过实现error接口来表示。Go语言的标准库中提供了一些函数和方法来处理错误,如返回error类型的函数、panic和recover函数等。通过这些函数和方法,可以实现错误的捕获、处理和传递。请解释一下Go语言中的闭包和defer关键字
闭包是一种函数,它可以访问在函数定义体外部的变量。在Go语言中,闭包可以用于实现一些高级的功能,如延迟执行、并发控制、事件驱动等。 defer语句用于在函数返回前执行一些清理操作,如关闭文件、解锁资源等。在Go语言中,defer语句会在函数返回前被执行,即使函数发生了panic也会被执行。Golang 中的 goroutine 是什么?它与线程的区别是什么?
goroutine 是 Golang 中的轻量级线程,它可以在一个 CPU 核心上并发执行多个任务。 与传统的线程相比,goroutine 的创建和销毁代价较小,且可以利用 Golang 内置的调度器进行高效的调度。此外,Golang 中的 goroutine 采用协作式调度,即 goroutine 需要主动让出 CPU 时间片,而不是像线程那样由操作系统进行抢占式调度。这使得 goroutine 可以更好地利用 CPU 时间,并且更容易避免竞态条件和死锁等并发问题。Golang 中的 interface 是什么?它有什么作用?如何使用它?
nterface 是 Golang 中的一种类型,用于定义对象的行为。interface 定义了对象应该具有的方法集合,但不提供方法的实现。一个对象只要实现了 interface 中定义的所有方法,就可以被认为是实现了该 interface。interface 可以用于实现多态性,使得代码更加灵活和可扩展。要使用 interface,需要先定义 interface,然后定义实现该 interface 的对象。



